Diagnosing Biased Inference with Divergences¶
** PyMC3 port of Michael Betancourt’s post on ms-stan. For detailed explanation of the underlying mechanism please check the original post and Betancourt’s excellent paper.**
Bayesian statistics is all about building your model and estimating the parameters in the model. However, due to limitations in our current mathematical understanding and computation capacity, naive or direct parameterization of our probability model often ran into problem (you can check out Thomas Wiecki’s blog post on the same issue in PyMC3). Suboptimal parameterization is often lead to slow sampling, and more problematic, biased MCMC estimators.
\[\mathbb{E}{\pi} [ f ] = \int \mathrm{d}q \, \pi (q) \, f(q),\]using the states of a Markov chain, \({q{0}, \ldots, q_{N} }\),
\[\mathbb{E}{\pi} [ f ] \approx \hat{f}{N} = \frac{1}{N + 1} \sum_{n = 0}^{N} f(q_{n}).\]
\[\lim_{N \rightarrow \infty} \hat{f}{N} = \mathbb{E}{\pi} [ f ].\]
In this notebook we aim to replicated the identification of divergences
sample and the underlying pathologies in PyMC3 similar to the
original
post.
In [1]:
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sb
import pandas as pd
import pymc3 as pm
%config InlineBackend.figure_format = 'retina'
%matplotlib inline
The Eight Schools Model¶
The hierarchical model of the the Eight Schools dataset (Rubin 1981) as seen in
Stan:\[\mu \sim \mathcal{N}(0, 5)\]\[\tau \sim \text{Half-Cauchy}(0, 5)\]\[\theta_{n} \sim \mathcal{N}(\mu, \tau)\]\[y_{n} \sim \mathcal{N}(\theta_{n}, \sigma_{n}),\]where \(n \in \{1, \ldots, 8 \}\) and the \(\{ y_{n}, \sigma_{n} \}\) are given as data.
Inferring the hierarchical hyperparameters, \(\mu\) and \(\sigma\), together with the group-level parameters, \(\theta_{1}, \ldots, \theta_{8}\), allows the model to pool data across the groups and reduce their posterior variance. Unfortunately, the direct centered parameterization also squeezes the posterior distribution into a particularly challenging geometry that obstructs geometric ergodicity and hence biases MCMC estimation.
In [2]:
# Data of the Eight Schools Model
J = 8
y = np.asarray([28, 8, -3, 7, -1, 1, 18, 12], dtype=float)
sigma = np.asarray([15, 10, 16, 11, 9, 11, 10, 18], dtype=float)
# tau = 25.
A Centered Eight Schools Implementation¶
Stan model:
data {
int<lower=0> J;
real y[J];
real<lower=0> sigma[J];
}
parameters {
real mu;
real<lower=0> tau;
real theta[J];
}
model {
mu ~ normal(0, 5);
tau ~ cauchy(0, 5);
theta ~ normal(mu, tau);
y ~ normal(theta, sigma);
}
Similarly, we can easily implemented it in PyMC3
In [4]:
with pm.Model() as Centered_eight:
mu = pm.Normal('mu', mu=0, sd=5)
tau = pm.HalfCauchy('tau', beta=5)
theta = pm.Normal('theta', mu=mu, sd=tau, shape=J)
obs = pm.Normal('obs', mu=theta, sd=sigma, observed=y)
Unfortunately, this direct implementation of the model exhibits a
pathological geometry that frustrates geometric ergodicity. Even
more worrisome, the resulting bias is subtle and may not be obvious
upon inspection of the Markov chain alone. To understand this bias,
let's consider first a short Markov chain, commonly used when
computational expediency is a motivating factor, and only afterwards
a longer Markov chain.
A Dangerously-Short Markov Chain¶
In [7]:
with Centered_eight:
short_trace = pm.sample(600, init=None, njobs=2, tune=500)
Assigned NUTS to mu
Assigned NUTS to tau_log_
Assigned NUTS to theta
100%|██████████| 600/600 [00:01<00:00, 354.50it/s]
PyMC3 we fit 2 chains with
600 sample each instead.
In [20]:
print(pm.diagnostics.gelman_rubin(short_trace))
print('')
print(pm.diagnostics.effective_n(short_trace))
{'theta': array([ 1.01466455, 1.00153203, 1.00351269, 1.009334 , 0.99977168,
1.00057635, 1.0159455 , 1.00228008]), 'tau_log_': 1.0439591442751275, 'mu': 1.0081977447110899, 'tau': 1.0164411689259558}
{'theta': array([ 274., 384., 311., 358., 282., 343., 263., 409.]), 'tau_log_': 59.0, 'mu': 182.0, 'tau': 88.0}
Moreover, the trace plots all look fine. Let’s consider, for example, the hierarchical standard deviation \(\tau\), or more specifically, its logarithm, \(log(\tau)\). Because \(\tau\) is constrained to be positive, its logarithm will allow us to better resolve behavior for small values. Indeed the chains seems to be exploring both small and large values reasonably well,
In [23]:
# plot the trace of log(tau)
pm.traceplot(short_trace, varnames=['tau_log_'])
plt.show()

Unfortunately, the resulting estimate for the mean of \(log(\tau)\) is strongly biased away from the true value, here shown in grey.
In [27]:
# plot the estimate for the mean of log(τ) cumulating mean
logtau = short_trace['tau_log_']
mlogtau = [np.mean(logtau[:i]) for i in np.arange(1, len(logtau))]
plt.figure(figsize=(15, 4))
plt.axhline(0.7657852, lw=2.5, color='gray')
plt.plot(mlogtau, lw=2.5)
plt.ylim(0, 2)
plt.xlabel('Iteration')
plt.ylabel('MCMC mean of log(tau)')
plt.title('MCMC estimation of log(tau)')
plt.show()
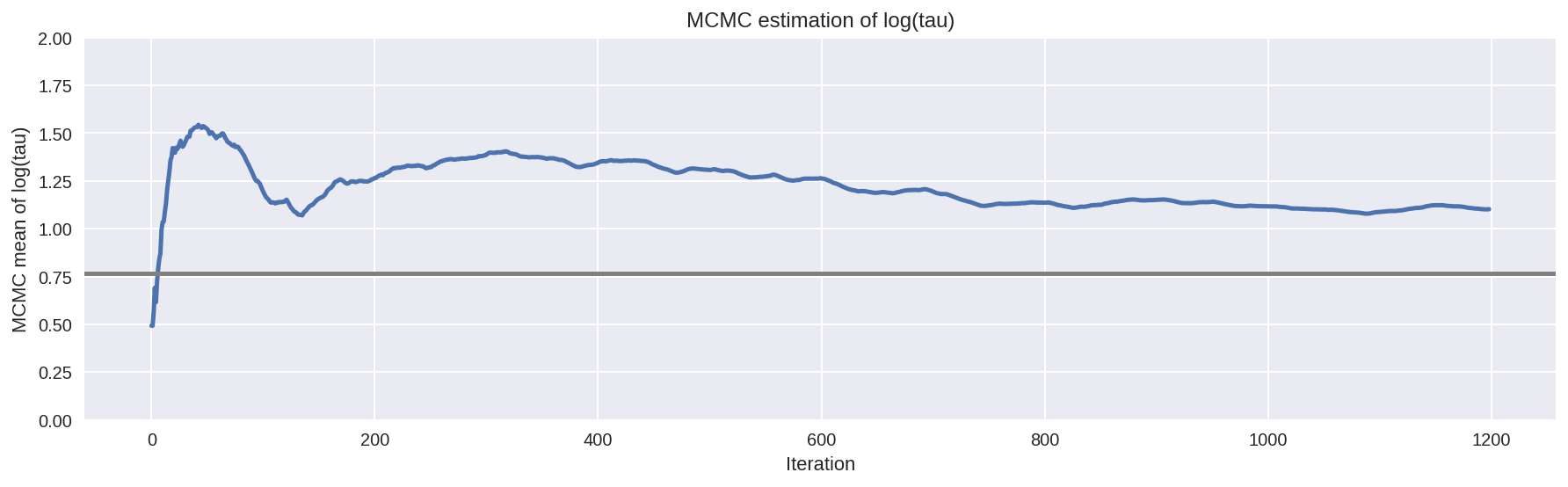
Hamiltonian Monte Carlo, however, is not so oblivious to these issues as 2% of the iterations in our lone Markov chain ended with a divergence.
In [28]:
# display the total number and percentage of divergent
divergent = short_trace['diverging']
print('Number of Divergent %d' % divergent.nonzero()[0].size)
divperc = divergent.nonzero()[0].size/len(short_trace)
print('Percentage of Divergent %.5f' % divperc)
Number of Divergent 14
Percentage of Divergent 0.02333
Even with a single short chain these divergences are able to identity the bias and advise skepticism of any resulting MCMC estimators.
Additionally, because the divergent transitions, here shown here in green, tend to be located near the pathologies we can use them to identify the location of the problematic neighborhoods in parameter space.
In [38]:
# scatter plot between log(tau) and theta[0]
# for the identifcation of the problematic neighborhoods in parameter space
theta_trace = short_trace['theta']
theta0 = theta_trace[:, 0]
plt.figure(figsize=(10, 6))
plt.scatter(theta0[divergent == 0], logtau[divergent == 0], color='r')
plt.scatter(theta0[divergent == 1], logtau[divergent == 1], color='g')
plt.axis([-20, 50, -6, 4])
plt.ylabel('log(tau)')
plt.xlabel('theta[0]')
plt.title('scatter plot between log(tau) and theta[1]')
plt.show()
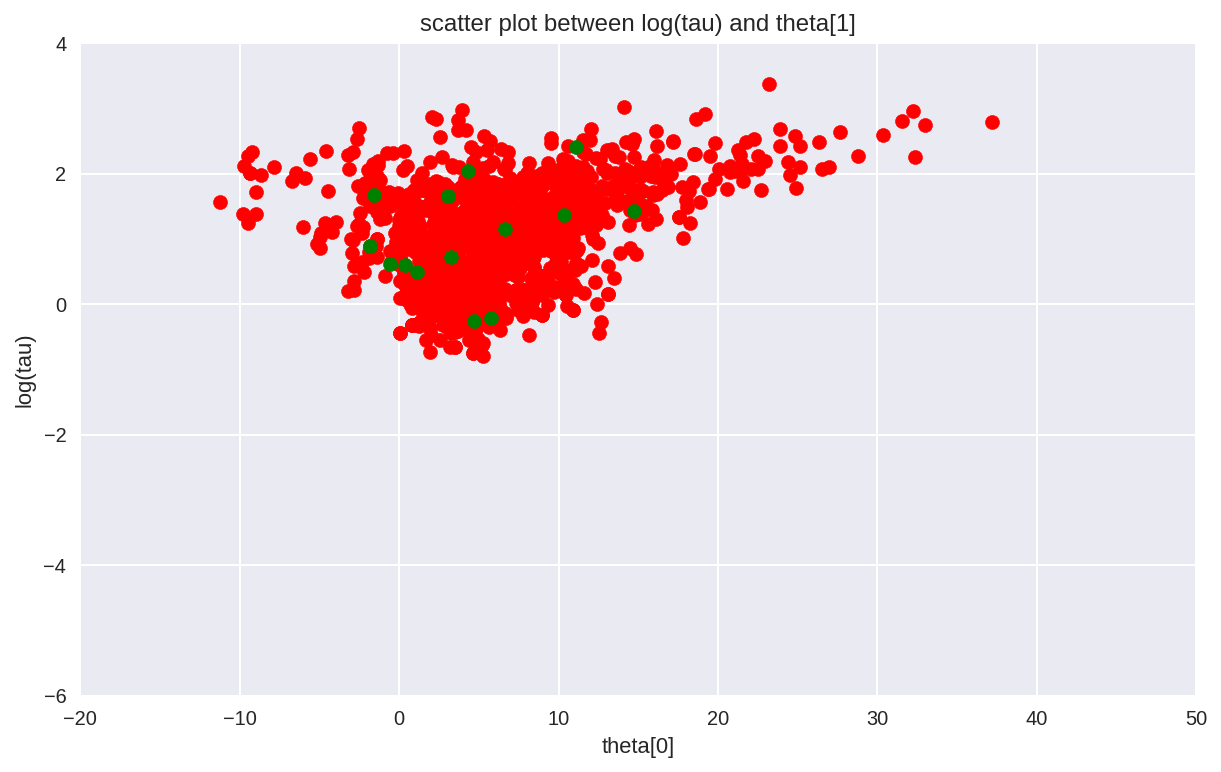
In the current example, the pathological samples from the trace is not
necessary concentrated at the funnel (unlike in Stan), the follow
figure is from the the original
post
as comparison.
In Stan the divergences are clustering at small values of
\(\tau\) where the hierarchical distribution, and hence all of the
group-level \(\theta_{n}\), are squeezed together. Eventually this
squeezing would yield the funnel geometry infamous to hierarchical
models, but here it appears that the Hamiltonian Markov chain is
diverging before it can fully explore the neck of the funnel.
In [41]:
# A small wrapper function for displaying the MCMC sampler diagnostics as above
def report_trace(trace):
# plot the trace of log(tau)
pm.traceplot(trace, varnames=['tau_log_'])
# plot the estimate for the mean of log(τ) cumulating mean
logtau = trace['tau_log_']
mlogtau = [np.mean(logtau[:i]) for i in np.arange(1, len(logtau))]
plt.figure(figsize=(15, 4))
plt.axhline(0.7657852, lw=2.5, color='gray')
plt.plot(mlogtau, lw=2.5)
plt.ylim(0, 2)
plt.xlabel('Iteration')
plt.ylabel('MCMC mean of log(tau)')
plt.title('MCMC estimation of log(tau)')
plt.show()
# display the total number and percentage of divergent
divergent = trace['diverging']
print('Number of Divergent %d' % divergent.nonzero()[0].size)
divperc = divergent.nonzero()[0].size/len(trace)
print('Percentage of Divergent %.5f' % divperc)
# scatter plot between log(tau) and theta[0]
# for the identifcation of the problematic neighborhoods in parameter space
theta_trace = trace['theta']
theta0 = theta_trace[:, 0]
plt.figure(figsize=(10, 6))
plt.scatter(theta0[divergent == 0], logtau[divergent == 0], color='r')
plt.scatter(theta0[divergent == 1], logtau[divergent == 1], color='g')
plt.axis([-20, 50, -6, 4])
plt.ylabel('log(tau)')
plt.xlabel('theta[0]')
plt.title('scatter plot between log(tau) and theta[1]')
plt.show()
A Safer, Longer Markov Chain¶
Given the potential insensitivity of split \(\hat{R}\) on single short chains,Stanrecommend always running multiple chains as long as possible to have the best chance to observe any obstructions to geometric ergodicity. Because it is not always possible to run long chains for complex models, however, divergences are an incredibly powerful diagnostic for biased MCMC estimation.
In [46]:
with Centered_eight:
longer_trace = pm.sample(5000, init=None, njobs=2, tune=1000)
report_trace(longer_trace)
Assigned NUTS to mu
Assigned NUTS to tau_log_
Assigned NUTS to theta
100%|██████████| 5000/5000 [00:11<00:00, 444.46it/s]

Number of Divergent 39
Percentage of Divergent 0.00780
In [47]:
print(pm.diagnostics.gelman_rubin(longer_trace))
print('')
print(pm.diagnostics.effective_n(longer_trace))
{'theta': array([ 1.00037593, 0.99990022, 1.00114791, 0.9999347 , 1.00259776,
1.00022565, 1.00152861, 0.99992059]), 'tau_log_': 1.0398125400857179, 'mu': 1.0006934326362604, 'tau': 1.0208315582727976}
{'theta': array([ 1953., 2127., 2155., 2106., 1382., 2054., 988., 2195.]), 'tau_log_': 72.0, 'mu': 1024.0, 'tau': 101.0}
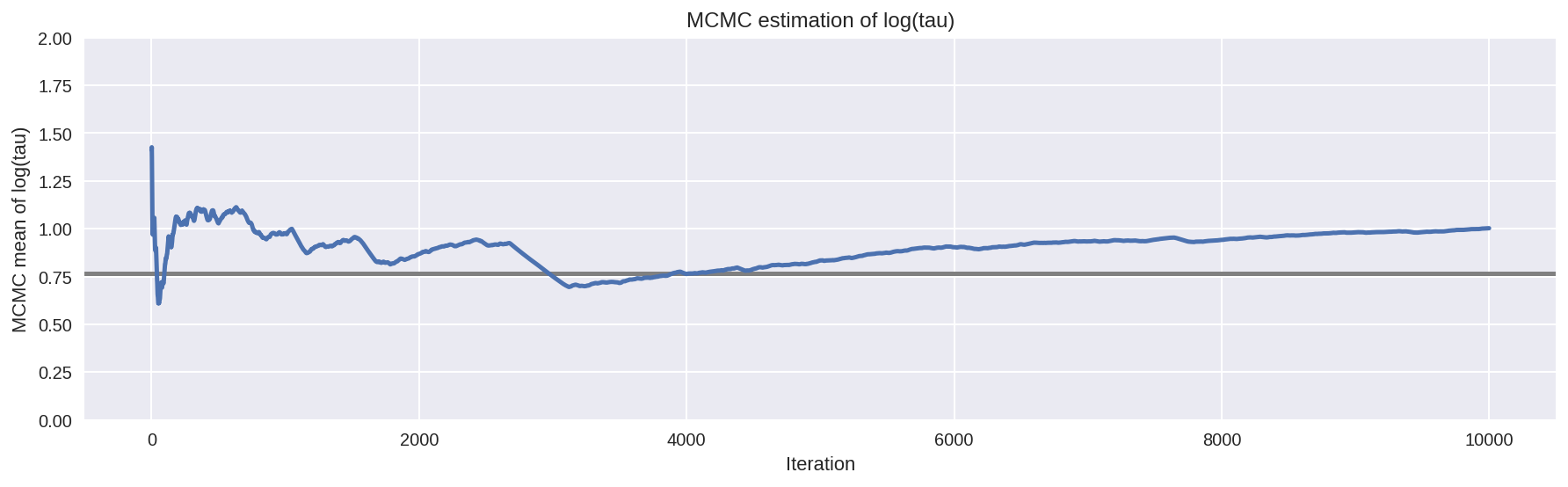
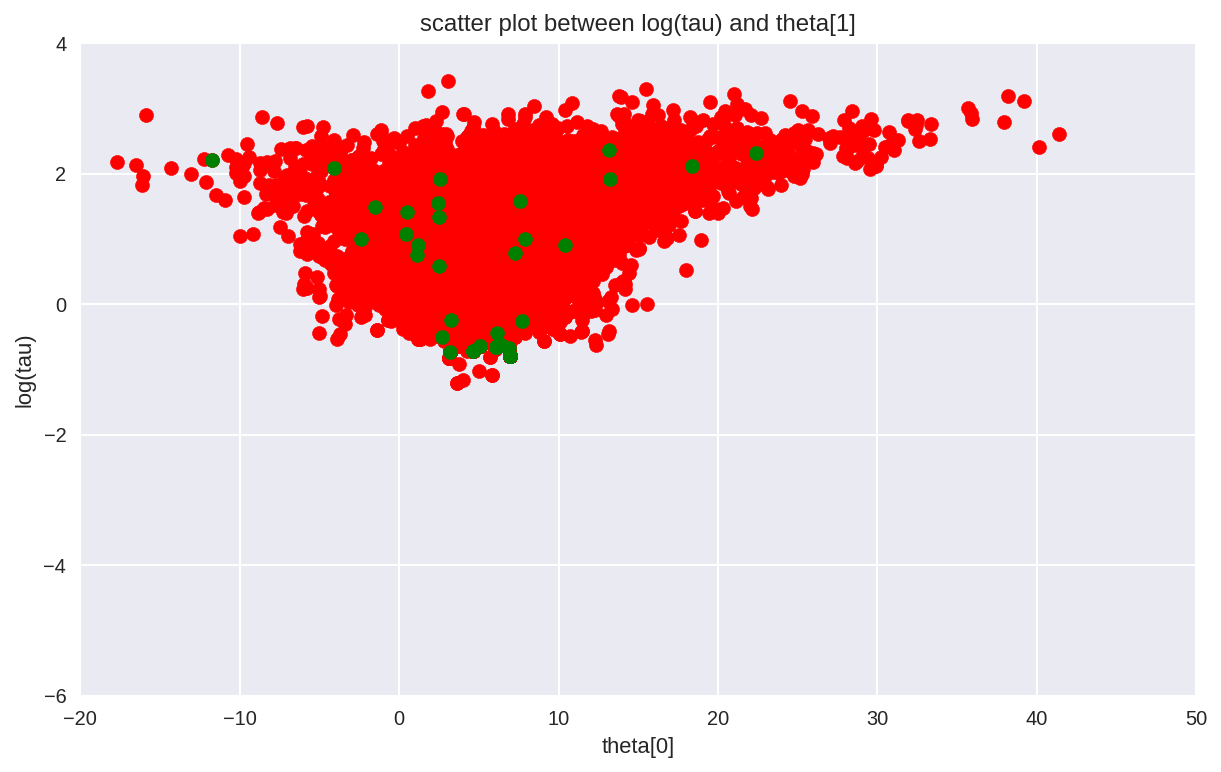
Similar to the result in Stan, \(\hat{R}\) does not indicate
any serious issues. However, the effective sample size per iteration
has drastically fallen, indicating that we are exploring less
efficiently the longer we run. This odd behavior is a clear sign
that something problematic is afoot. As shown in the trace plot, the
chain occasionally “sticking” as it approaches small values of
\(\tau\), exactly where we saw the divergences concentrating.
This is a clear indication of the underlying pathologies. These
sticky intervals induce severe oscillations in the MCMC estimators
early on, until they seem to finally settle into biased values.
In fact the sticky intervals are the Markov chain trying to correct the biased exploration. If we ran the chain even longer then it would eventually get stuck again and drag the MCMC estimator down towards the true value. Given an infinite number of iterations this delicate balance asymptotes to the true expectation as we’d expect given the consistency guarantee of MCMC. Stopping the after any finite number of iterations, however, destroys this balance and leaves us with a significant bias.
More details can be found in Betancourt’s recent paper.
Mitigating Divergences by Adjusting PyMC3’s Adaptation Routine¶
Divergences in Hamiltonian Monte Carlo arise when the Hamiltonian transition encounters regions of extremely large curvature, such as the opening of the hierarchical funnel. Unable to accurate resolve these regions, the transition malfunctions and flies off towards infinity. With the transitions unable to completely explore these regions of extreme curvature, we lose geometric ergodicity and our MCMC estimators become biased.
Algorithm implemented in
Stanuses a heuristic to quickly identify these misbehaving trajectories, and hence label divergences, without having to wait for them to run all the way to infinity. This heuristic can be a bit aggressive, however, and sometimes label transitions as divergent even when we have not lost geometric ergodicity.To resolve this potential ambiguity we can adjust the step size, \(\epsilon\), of the Hamiltonian transition. The smaller the step size the more accurate the trajectory and the less likely it will be mislabeled as a divergence. In other words, if we have geometric ergodicity between the Hamiltonian transition and the target distribution then decreasing the step size will reduce and then ultimately remove the divergences entirely. If we do not have geometric ergodicity, however, then decreasing the step size will not completely remove the divergences.
Like Stan, the step size in PyMC3 is tuned automatically during
warm up, but we can coerce smaller step sizes by tweaking the
configuration of PyMC3‘s adaptation routine. In particular, we can
increase the target_accept parameter from its default value of 0.8
closer to its maximum value of 1.
Adjusting Adaptation Routine¶
In [48]:
with Centered_eight:
step = pm.NUTS(target_accept=.85)
fit_cp85 = pm.sample(5000, step=step, init=None, njobs=2, tune=1000)
with Centered_eight:
step = pm.NUTS(target_accept=.90)
fit_cp90 = pm.sample(5000, step=step, init=None, njobs=2, tune=1000)
with Centered_eight:
step = pm.NUTS(target_accept=.95)
fit_cp95 = pm.sample(5000, step=step, init=None, njobs=2, tune=1000)
with Centered_eight:
step = pm.NUTS(target_accept=.99)
fit_cp99 = pm.sample(5000, step=step, init=None, njobs=2, tune=1000)
100%|██████████| 5000/5000 [00:11<00:00, 450.42it/s]
100%|██████████| 5000/5000 [00:15<00:00, 325.33it/s]
100%|██████████| 5000/5000 [00:19<00:00, 258.28it/s]
100%|██████████| 5000/5000 [00:36<00:00, 138.24it/s]
In [50]:
df = pd.DataFrame([longer_trace['step_size'].mean(),
fit_cp85['step_size'].mean(),
fit_cp90['step_size'].mean(),
fit_cp95['step_size'].mean(),
fit_cp99['step_size'].mean()], columns=['Step_size'])
df['Divergent'] = pd.Series([longer_trace['diverging'].sum(),
fit_cp85['diverging'].sum(),
fit_cp90['diverging'].sum(),
fit_cp95['diverging'].sum(),
fit_cp99['diverging'].sum()])
df['delta'] = pd.Series(['.80', '.85', '.90', '.95', '.99'])
print(df)
Step_size Divergent delta
0 0.206308 39 .80
1 0.193720 70 .85
2 0.186060 57 .90
3 0.136067 10 .95
4 0.060498 4 .99
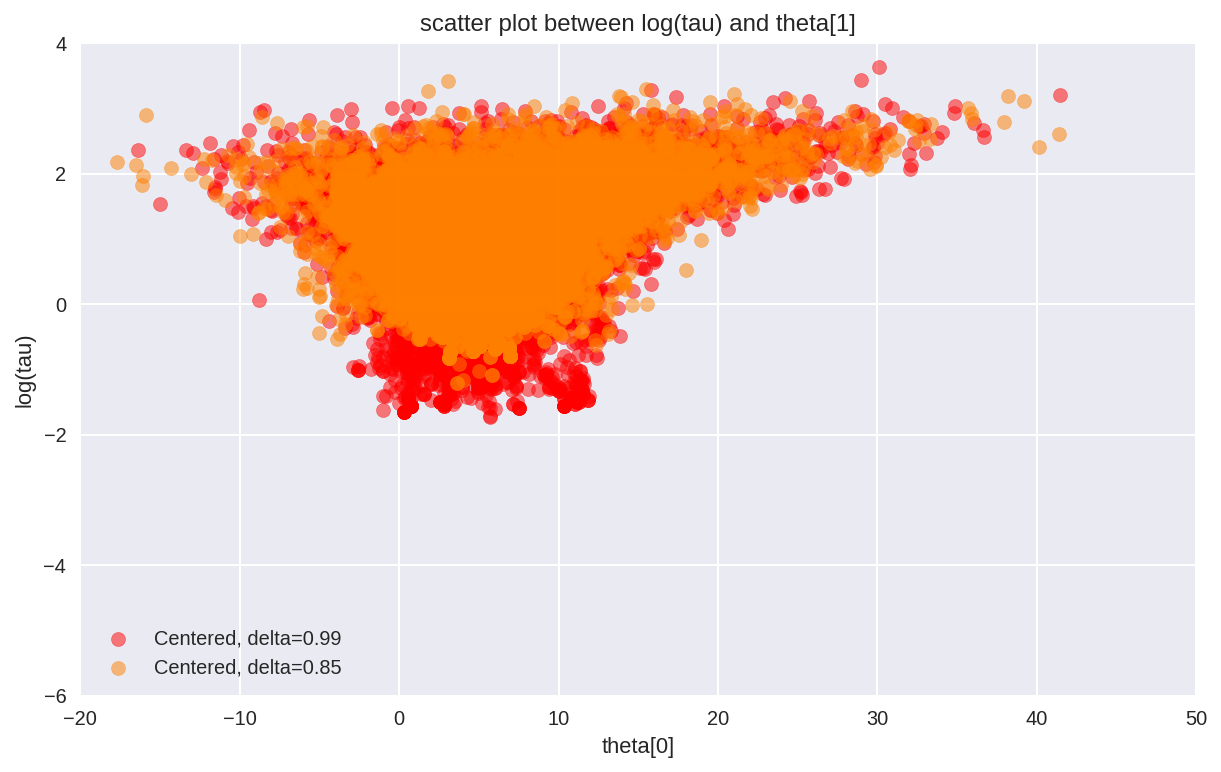
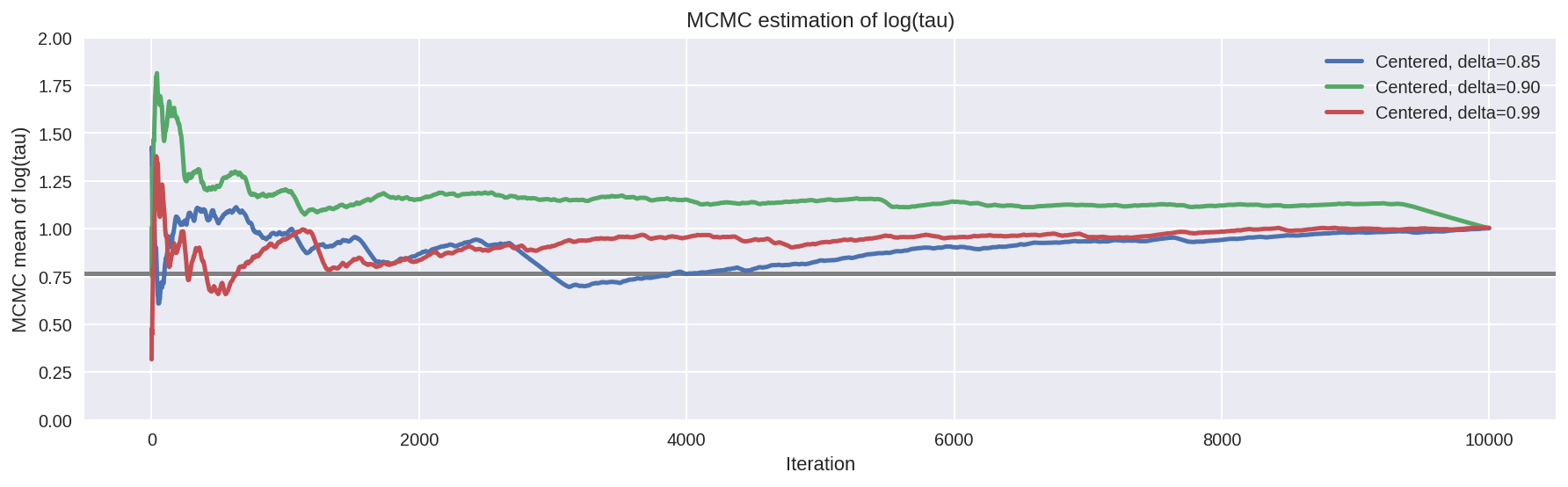
Interestingly, unlike in Stan, the number of divergent transitions
decrease since we increased the adapt_delta and decreased the step
size. > This behavior also has a nice geometric intuition. The more we
decrease the step size the more the Hamiltonian Markov chain can explore
the neck of the funnel. Consequently, the marginal posterior
distribution for \(log (\tau)\) stretches further and further
towards negative values with the decreasing step size.
Since in PyMC3 after tuning we have a smaller step size than
Stan, the geometery is better explored. > However, the Hamiltonian
transition is still not geometrically ergodic with respect to the
centered implementation of the Eight Schools model. Indeed, this is
expected given the observed bias.
In [54]:
theta0 = longer_trace['theta'][:, 0]
logtau0 = longer_trace['tau_log_']
divergent0 = longer_trace['diverging']
theta1 = fit_cp99['theta'][:, 0]
logtau1 = fit_cp99['tau_log_']
divergent1 = fit_cp99['diverging']
plt.figure(figsize=(10, 6))
plt.scatter(theta1[divergent1 == 0], logtau1[divergent1 == 0],
color='r', alpha=.5, label='Centered, delta=0.99')
plt.scatter(theta0[divergent0 == 0], logtau0[divergent0 == 0],
color=[1, .5, 0], alpha=.5, label='Centered, delta=0.85')
plt.axis([-20, 50, -6, 4])
plt.ylabel('log(tau)')
plt.xlabel('theta[0]')
plt.title('scatter plot between log(tau) and theta[1]')
plt.legend()
plt.show()
logtau2 = fit_cp90['tau_log_']
plt.figure(figsize=(15, 4))
plt.axhline(0.7657852, lw=2.5, color='gray')
mlogtau0 = [np.mean(logtau0[:i]) for i in np.arange(1, len(logtau0))]
plt.plot(mlogtau0, label='Centered, delta=0.85', lw=2.5)
mlogtau2 = [np.mean(logtau2[:i]) for i in np.arange(1, len(logtau2))]
plt.plot(mlogtau2, label='Centered, delta=0.90', lw=2.5)
mlogtau1 = [np.mean(logtau1[:i]) for i in np.arange(1, len(logtau1))]
plt.plot(mlogtau1, label='Centered, delta=0.99', lw=2.5)
plt.ylim(0, 2)
plt.xlabel('Iteration')
plt.ylabel('MCMC mean of log(tau)')
plt.title('MCMC estimation of log(tau)')
plt.legend()
plt.show()
A Non-Centered Eight Schools Implementation¶
Although reducing the step size improves exploration, ultimately it only reveals the true extent the pathology in the centered implementation. Fortunately, there is another way to implement hierarchical models that does not suffer from the same pathologies.
In a non-centered parameterization we do not try to fit the group-level parameters directly, rather we fit a latent Gaussian variable from which we can recover the group-level parameters with a scaling and a translation.
\[\mu \sim \mathcal{N}(0, 5)\]\[\tau \sim \text{Half-Cauchy}(0, 5)\]\[\tilde{\theta}_{n} \sim \mathcal{N}(0, 1)\]\[\theta_{n} = \mu + \tau \cdot \tilde{\theta}_{n}.\]
Stan model:
data {
int<lower=0> J;
real y[J];
real<lower=0> sigma[J];
}
parameters {
real mu;
real<lower=0> tau;
real theta_tilde[J];
}
transformed parameters {
real theta[J];
for (j in 1:J)
theta[j] = mu + tau * theta_tilde[j];
}
model {
mu ~ normal(0, 5);
tau ~ cauchy(0, 5);
theta_tilde ~ normal(0, 1);
y ~ normal(theta, sigma);
}
In [57]:
with pm.Model() as NonCentered_eight:
mu = pm.Normal('mu', mu=0, sd=5)
tau = pm.HalfCauchy('tau', beta=5)
theta_tilde = pm.Normal('theta_t', mu=0, sd=1, shape=J)
theta = pm.Deterministic('theta', mu + tau * theta_tilde)
obs = pm.Normal('obs', mu=theta, sd=sigma, observed=y)
In [58]:
with NonCentered_eight:
step = pm.NUTS(target_accept=.80)
fit_ncp80 = pm.sample(5000, step=step, init=None, njobs=2, tune=1000)
100%|██████████| 5000/5000 [00:05<00:00, 854.95it/s]
In [59]:
print(pm.diagnostics.gelman_rubin(fit_ncp80))
print('')
print(pm.diagnostics.effective_n(fit_ncp80))
{'theta': array([ 0.9999017 , 0.99990126, 0.99994554, 0.99991853, 0.99992781,
0.99990295, 0.99990909, 0.99991026]), 'tau_log_': 1.0005729430235684, 'tau': 0.99990735598654512, 'mu': 0.99990583189162452, 'theta_t': array([ 0.99990015, 1.00004939, 0.99990031, 0.99990172, 0.99990554,
0.99990178, 1.00008856, 0.99991732])}
{'theta': array([ 8024., 10000., 9338., 10000., 9299., 9330., 8541.,
8856.]), 'tau_log_': 3741.0, 'tau': 4488.0, 'mu': 10000.0, 'theta_t': array([ 10000., 10000., 10000., 10000., 10000., 10000., 10000.,
10000.])}
As shown above, the effective sample size per iteration has drastically improved, and the trace plots no longer show any “stickyness”. However, we do still see the rare divergence. These infrequent divergences do not seem concentrate anywhere in parameter space, which is indicative of the divergences being false positives.
In [60]:
report_trace(fit_ncp80)

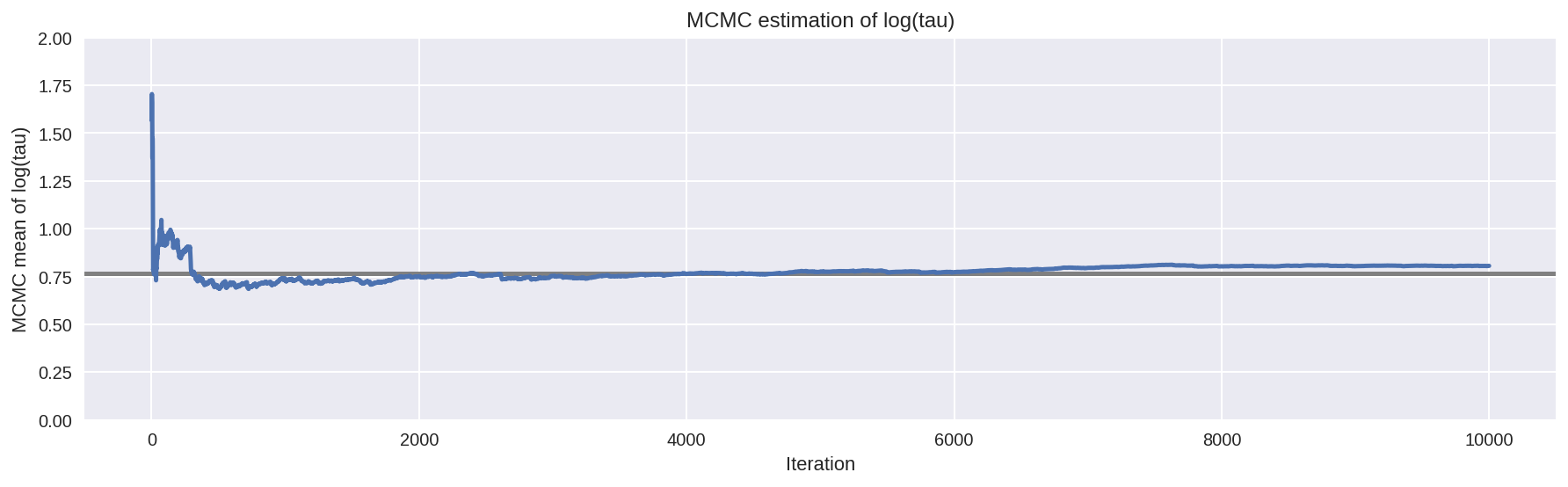
Number of Divergent 14
Percentage of Divergent 0.00280
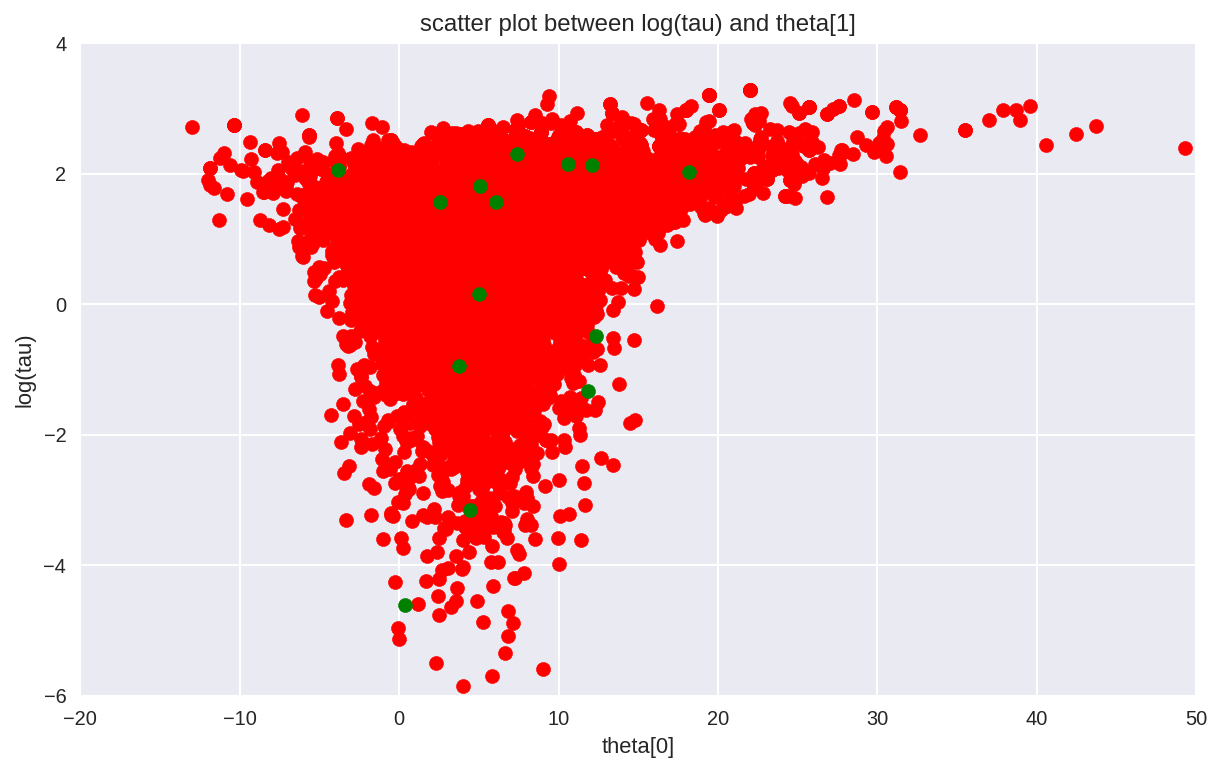
As expected of false positives, we can remove the divergences entirely by decreasing the step size,
In [61]:
with NonCentered_eight:
step = pm.NUTS(target_accept=.90)
fit_ncp90 = pm.sample(5000, step=step, init=None, njobs=2, tune=1000)
# display the total number and percentage of divergent
divergent = fit_ncp90['diverging']
print('Number of Divergent %d' % divergent.nonzero()[0].size)
100%|██████████| 5000/5000 [00:06<00:00, 721.82it/s]
Number of Divergent 0
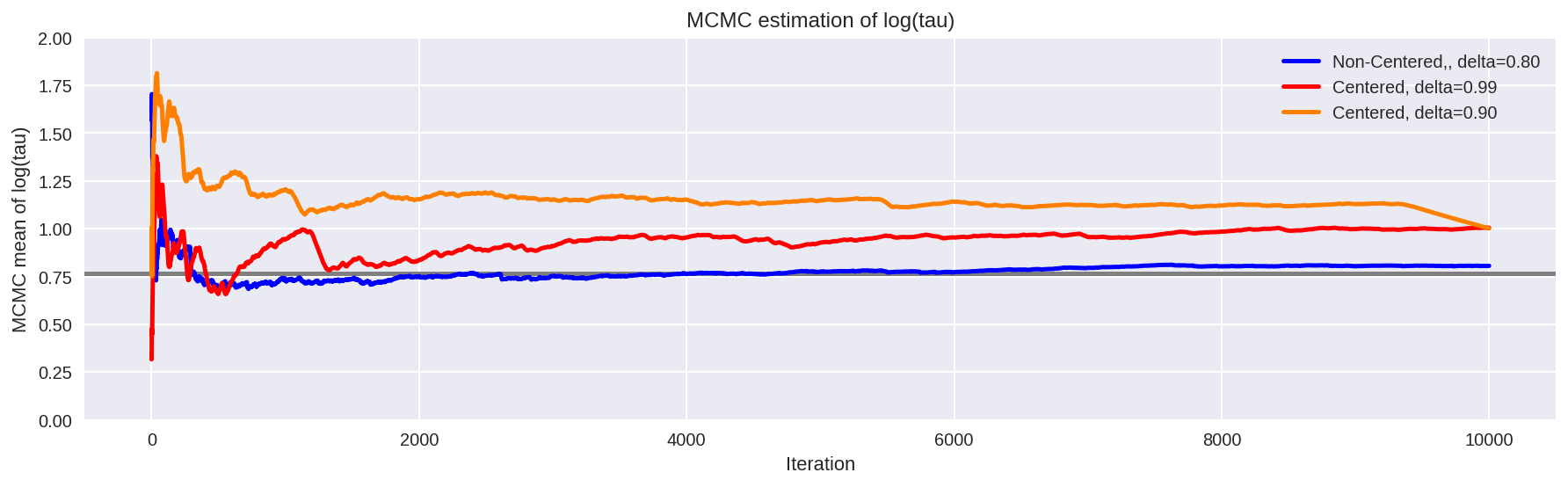
The more agreeable geometry of the non-centered implementation allows the Markov chain to explore deep into the neck of the funnel, capturing even the smallest values of \(\tau\) that are consistent with the measurements. Consequently, MCMC estimators from the non-centered chain rapidly converge towards their true expectation values.
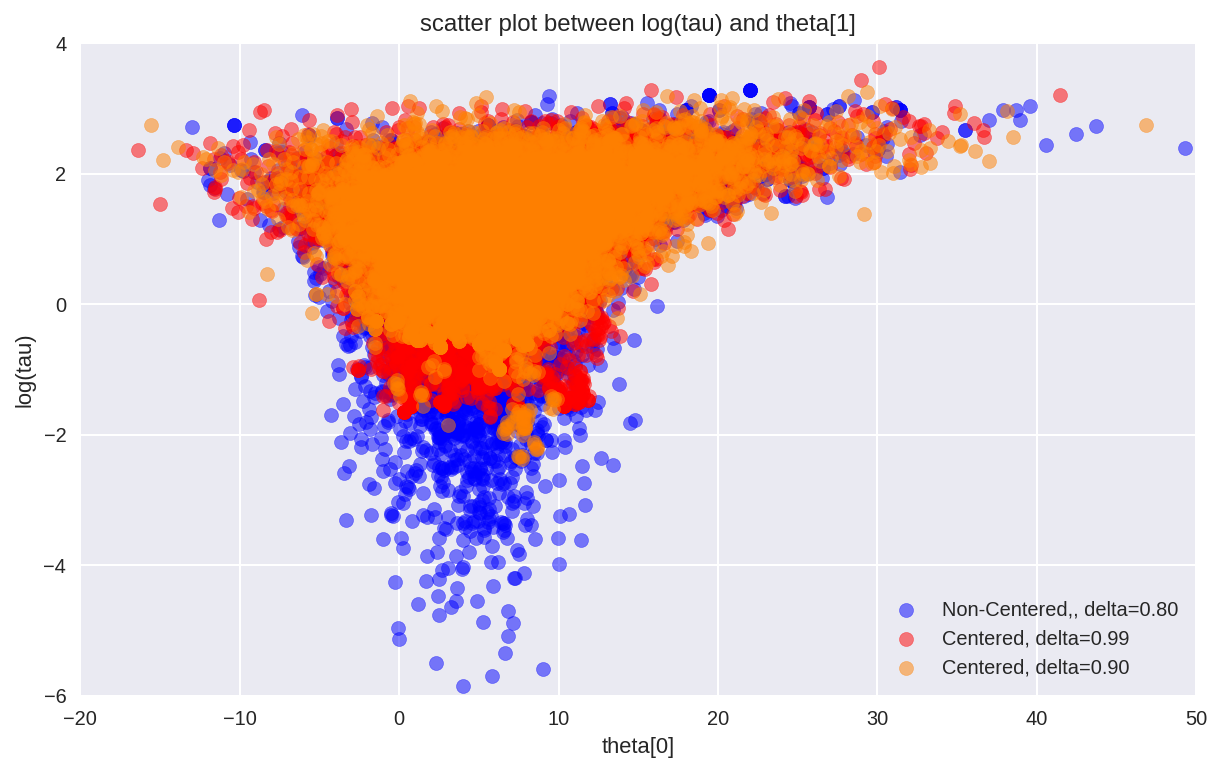
In [65]:
theta0 = fit_cp90['theta'][:, 0]
logtau0 = fit_cp90['tau_log_']
divergent0 = fit_cp90['diverging']
theta1 = fit_cp99['theta'][:, 0]
logtau1 = fit_cp99['tau_log_']
divergent1 = fit_cp99['diverging']
thetan = fit_ncp80['theta'][:, 0]
logtaun = fit_ncp80['tau_log_']
divergentn = fit_ncp80['diverging']
plt.figure(figsize=(10, 6))
plt.scatter(thetan[divergentn == 0], logtaun[divergentn == 0],
color='b', alpha=.5, label='Non-Centered, delta=0.80')
plt.scatter(theta1[divergent1 == 0], logtau1[divergent1 == 0],
color='r', alpha=.5, label='Centered, delta=0.99')
plt.scatter(theta0[divergent0 == 0], logtau0[divergent0 == 0],
color=[1, 0.5, 0], alpha=.5, label='Centered, delta=0.90')
plt.axis([-20, 50, -6, 4])
plt.ylabel('log(tau)')
plt.xlabel('theta[0]')
plt.title('scatter plot between log(tau) and theta[1]')
plt.legend()
plt.show()
plt.figure(figsize=(15, 4))
plt.axhline(0.7657852, lw=2.5, color='gray')
mlogtaun = [np.mean(logtaun[:i]) for i in np.arange(1, len(logtaun))]
plt.plot(mlogtaun, color='b', lw=2.5, label='Non-Centered, delta=0.80')
mlogtau1 = [np.mean(logtau1[:i]) for i in np.arange(1, len(logtau1))]
plt.plot(mlogtau1, color='r', lw=2.5, label='Centered, delta=0.99')
mlogtau0 = [np.mean(logtau0[:i]) for i in np.arange(1, len(logtau0))]
plt.plot(mlogtau0, color=[1, 0.5, 0], lw=2.5, label='Centered, delta=0.90')
plt.ylim(0, 2)
plt.xlabel('Iteration')
plt.ylabel('MCMC mean of log(tau)')
plt.title('MCMC estimation of log(tau)')
plt.legend()
plt.show()
In [ ]: