API quickstart¶
In [1]:
%matplotlib inline
import numpy as np
import theano.tensor as tt
import pymc3 as pm
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_context('notebook')
1. Model creation¶
Models in PyMC3 are centered around the Model class. It has
references to all random variables (RVs) and computes the model logp and
its gradients. Usually, you would instantiate it as part of a with
context:
In [2]:
with pm.Model() as model:
# Model definition
pass
We discuss RVs further below but let’s create a simple model to explore
the Model class.
In [3]:
with pm.Model() as model:
mu = pm.Normal('mu', mu=0, sd=1)
obs = pm.Normal('obs', mu=mu, sd=1, observed=np.random.randn(100))
In [4]:
model.basic_RVs
Out[4]:
[mu, obs]
In [5]:
model.free_RVs
Out[5]:
[mu]
In [6]:
model.observed_RVs
Out[6]:
[obs]
In [7]:
model.logp({'mu': 0})
Out[7]:
array(-130.93385991219947)
2. Probability Distributions¶
Every probabilistic program consists of observed and unobserved Random Variables (RVs). Observed RVs are defined via likelihood distributions, while unobserved RVs are defined via prior distributions. In PyMC3, probability distributions are available from the main module space:
In [8]:
help(pm.Normal)
Help on class Normal in module pymc3.distributions.continuous:
class Normal(pymc3.distributions.distribution.Continuous)
| Univariate normal log-likelihood.
|
| .. math::
|
| f(x \mid \mu, \tau) =
| \sqrt{\frac{\tau}{2\pi}}
| \exp\left\{ -\frac{\tau}{2} (x-\mu)^2 \right\}
|
| ======== ==========================================
| Support :math:`x \in \mathbb{R}`
| Mean :math:`\mu`
| Variance :math:`\dfrac{1}{\tau}` or :math:`\sigma^2`
| ======== ==========================================
|
| Normal distribution can be parameterized either in terms of precision
| or standard deviation. The link between the two parametrizations is
| given by
|
| .. math::
|
| \tau = \dfrac{1}{\sigma^2}
|
| Parameters
| ----------
| mu : float
| Mean.
| sd : float
| Standard deviation (sd > 0).
| tau : float
| Precision (tau > 0).
|
| Method resolution order:
| Normal
| pymc3.distributions.distribution.Continuous
| pymc3.distributions.distribution.Distribution
| builtins.object
|
| Methods defined here:
|
| __init__(self, mu=0, sd=None, tau=None, **kwargs)
| Initialize self. See help(type(self)) for accurate signature.
|
| logp(self, value)
|
| random(self, point=None, size=None, repeat=None)
|
| ----------------------------------------------------------------------
| Methods inherited from pymc3.distributions.distribution.Distribution:
|
| __getnewargs__(self)
|
| default(self)
|
| get_test_val(self, val, defaults)
|
| getattr_value(self, val)
|
| ----------------------------------------------------------------------
| Class methods inherited from pymc3.distributions.distribution.Distribution:
|
| dist(*args, **kwargs) from builtins.type
|
| ----------------------------------------------------------------------
| Static methods inherited from pymc3.distributions.distribution.Distribution:
|
| __new__(cls, name, *args, **kwargs)
| Create and return a new object. See help(type) for accurate signature.
|
| ----------------------------------------------------------------------
| Data descriptors inherited from pymc3.distributions.distribution.Distribution:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
In the PyMC3 module, the structure for probability distributions looks like this:
pymc3.distributions|- continuous|- discrete|- timeseries|- mixture
In [9]:
dir(pm.distributions.mixture)
Out[9]:
['Discrete',
'Distribution',
'Mixture',
'Normal',
'NormalMixture',
'__builtins__',
'__cached__',
'__doc__',
'__file__',
'__loader__',
'__name__',
'__package__',
'__spec__',
'all_discrete',
'bound',
'draw_values',
'generate_samples',
'get_tau_sd',
'logsumexp',
'np',
'tt']
Unobserved Random Variables¶
Every unobserved RV has the following calling signature: name (str), parameter keyword arguments. Thus, a normal prior can be defined in a model context like this:
In [10]:
with pm.Model():
x = pm.Normal('x', mu=0, sd=1)
As with the model, we can evaluate its logp:
In [11]:
x.logp({'x': 0})
Out[11]:
array(-0.9189385332046727)
Observed Random Variables¶
Observed RVs are defined just like unobserved RVs but require data to be
passed into the observed keyword argument:
In [12]:
with pm.Model():
obs = pm.Normal('x', mu=0, sd=1, observed=np.random.randn(100))
observed supports lists, numpy.ndarray, theano and
pandas data structures.
Deterministic transforms¶
PyMC3 allows you to freely do algebra with RVs in all kinds of ways:
In [13]:
with pm.Model():
x = pm.Normal('x', mu=0, sd=1)
y = pm.Gamma('y', alpha=1, beta=1)
plus_2 = x + 2
summed = x + y
squared = x**2
sined = pm.math.sin(x)
While these transformations work seamlessly, its results are not stored
automatically. Thus, if you want to keep track of a transformed
variable, you have to use pm.Determinstic:
In [14]:
with pm.Model():
x = pm.Normal('x', mu=0, sd=1)
plus_2 = pm.Deterministic('x plus 2', x + 2)
Note that plus_2 can be used in the identical way to above, we only
tell PyMC3 to keep track of this RV for us.
Automatic transforms of bounded RVs¶
In order to sample models more efficiently, PyMC3 automatically transforms bounded RVs to be unbounded.
In [15]:
with pm.Model() as model:
x = pm.Uniform('x', lower=0, upper=1)
When we look at the RVs of the model, we would expect to find x
there, however:
In [16]:
model.free_RVs
Out[16]:
[x_interval__]
x_interval__ represents x transformed to accept parameter values
between -inf and +inf. In the case of an upper and a lower bound, a
LogOdds transform is applied. Sampling in this transformed space
makes it easier for the sampler. PyMC3 also keeps track of the
non-transformed, bounded parameters. These are common determinstics (see
above):
In [17]:
model.deterministics
Out[17]:
[x]
When displaying results, PyMC3 will usually hide transformed parameters.
You can pass the include_transformed=True parameter to many
functions to see the transformed parameters that are used for sampling.
You can also turn transforms off:
In [18]:
with pm.Model() as model:
x = pm.Uniform('x', lower=0, upper=1, transform=None)
print(model.free_RVs)
[x]
Lists of RVs / higher-dimensional RVs¶
Above we have seen to how to create scalar RVs. In many models, you want multiple RVs. There is a tendency (mainly inherited from PyMC 2.x) to create list of RVs, like this:
In [19]:
with pm.Model():
x = [pm.Normal('x_{}'.format(i), mu=0, sd=1) for i in range(10)] # bad
However, even though this works it is quite slow and not recommended.
Instead, use the shape kwarg:
In [20]:
with pm.Model() as model:
x = pm.Normal('x', mu=0, sd=1, shape=10) # good
x is now a random vector of length 10. We can index into it or do
linear algebra operations on it:
In [21]:
with model:
y = x[0] * x[1] # full indexing is supported
x.dot(x.T) # Linear algebra is supported
Initialization with test_values¶
While PyMC3 tries to automatically initialize models it is sometimes
helpful to define initial values for RVs. This can be done via the
testval kwarg:
In [22]:
with pm.Model():
x = pm.Normal('x', mu=0, sd=1, shape=5)
x.tag.test_value
Out[22]:
array([ 0., 0., 0., 0., 0.])
In [23]:
with pm.Model():
x = pm.Normal('x', mu=0, sd=1, shape=5, testval=np.random.randn(5))
x.tag.test_value
Out[23]:
array([ 0.51093099, 0.78646267, -1.02921232, 0.65820029, 0.70385385])
This technique is quite useful to identify problems with model specification or initialization.
3. Inference¶
Once we have defined our model, we have to perform inference to approximate the posterior distribution. PyMC3 supports two broad classes of inference: sampling and variational inference.
3.1 Sampling¶
The main entry point to MCMC sampling algorithms is via the
pm.sample() function. By default, this function tries to auto-assign
the right sampler(s) and auto-initialize if you don’t pass anything.
In [24]:
with pm.Model() as model:
mu = pm.Normal('mu', mu=0, sd=1)
obs = pm.Normal('obs', mu=mu, sd=1, observed=np.random.randn(100))
trace = pm.sample(1000, tune=500)
Auto-assigning NUTS sampler...
Initializing NUTS using ADVI...
Average Loss = 143.54: 10%|█ | 20024/200000 [00:01<00:12, 14337.29it/s]
Convergence archived at 21000
Interrupted at 21,000 [10%]: Average Loss = 144.89
100%|██████████| 1500/1500 [00:00<00:00, 2730.61it/s]
As you can see, on a continuous model, PyMC3 assigns the NUTS sampler, which is very efficient even for complex models. PyMC3 also runs variational inference (i.e. ADVI) to find good starting parameters for the sampler. Here we draw 1000 samples from the posterior and allow the sampler to adjust its parameters in an additional 500 iterations. These 500 samples are discarded by default:
In [25]:
len(trace)
Out[25]:
1000
You can also run multiple chains in parallel using the njobs kwarg:
In [26]:
with pm.Model() as model:
mu = pm.Normal('mu', mu=0, sd=1)
obs = pm.Normal('obs', mu=mu, sd=1, observed=np.random.randn(100))
trace = pm.sample(njobs=4)
Auto-assigning NUTS sampler...
Initializing NUTS using ADVI...
Average Loss = 142.41: 22%|██▏ | 44484/200000 [00:02<00:08, 18649.61it/s]
Convergence archived at 46000
Interrupted at 46,000 [23%]: Average Loss = 143.02
100%|██████████| 1000/1000 [00:01<00:00, 928.24it/s]
Note, that we are now drawing 2000 samples, 500 samples for 4 chains each. The 500 tuning samples are discarded by default.
In [27]:
trace['mu'].shape
Out[27]:
(2000,)
In [28]:
trace.nchains
Out[28]:
4
In [29]:
trace.get_values('mu', chains=1).shape # get values of a single chain
Out[29]:
(500,)
PyMC3, offers a variety of other samplers, found in pm.step_methods.
In [30]:
list(filter(lambda x: x[0].isupper(), dir(pm.step_methods)))
Out[30]:
['BinaryGibbsMetropolis',
'BinaryMetropolis',
'CategoricalGibbsMetropolis',
'CauchyProposal',
'CompoundStep',
'ElemwiseCategorical',
'EllipticalSlice',
'HamiltonianMC',
'LaplaceProposal',
'Metropolis',
'MultivariateNormalProposal',
'NUTS',
'NormalProposal',
'PoissonProposal',
'SMC',
'Slice']
Commonly used step-methods besides NUTS are Metropolis and
Slice. For almost all continuous models, ``NUTS`` should be
preferred. There are hard-to-sample models for which NUTS will be
very slow causing many users to use Metropolis instead. This
practice, however, is rarely successful. NUTS is fast on simple models
but can be slow if the model is very complex or it is badly initialized.
In the case of a complex model that is hard for NUTS, Metropolis, while
faster, will have a very low effective sample size or not converge
properly at all. A better approach is to instead try to improve
initialization of NUTS, or reparameterize the model.
For completeness, other sampling methods can be passed to sample:
In [31]:
with pm.Model() as model:
mu = pm.Normal('mu', mu=0, sd=1)
obs = pm.Normal('obs', mu=mu, sd=1, observed=np.random.randn(100))
step = pm.Metropolis()
trace = pm.sample(1000, step=step)
100%|██████████| 1500/1500 [00:00<00:00, 9343.52it/s]
You can also assign variables to different step methods.
In [32]:
with pm.Model() as model:
mu = pm.Normal('mu', mu=0, sd=1)
sd = pm.HalfNormal('sd', sd=1)
obs = pm.Normal('obs', mu=mu, sd=sd, observed=np.random.randn(100))
step1 = pm.Metropolis(vars=[mu])
step2 = pm.Slice(vars=[sd])
trace = pm.sample(10000, step=[step1, step2], njobs=4)
100%|██████████| 10500/10500 [00:11<00:00, 890.12it/s]
3.2 Analyze sampling results¶
The most common used plot to analyze sampling results is the so-called trace-plot:
In [33]:
pm.traceplot(trace);
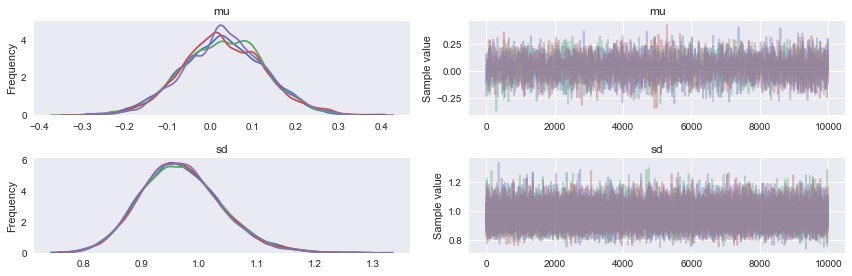
Another common metric to look at is R-hat, also known as the Gelman-Rubin statistic:
In [34]:
pm.gelman_rubin(trace)
Out[34]:
{'mu': 1.0003808153475398,
'sd': 0.99997655090314819,
'sd_log__': 0.9999720004991266}
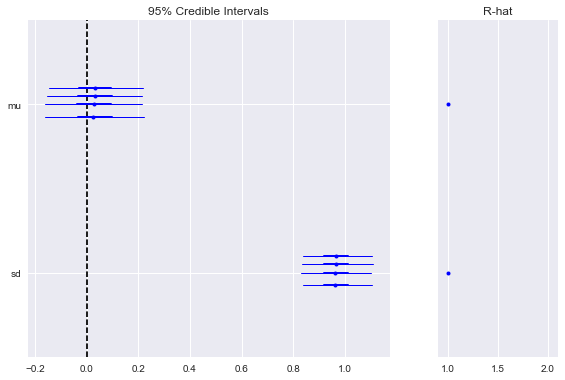
These are also part of the forestplot:
In [35]:
pm.forestplot(trace);
Finally, for a plot of the posterior that is inspired by the book Doing Bayesian Data Analysis, you can use the:
In [36]:
pm.plot_posterior(trace);

For high-dimensional models it becomes cumbersome to look at all
parameter’s traces. When using NUTS we can look at the energy plot
to assess problems of convergence:
In [37]:
with pm.Model() as model:
x = pm.Normal('x', mu=0, sd=1, shape=100)
trace = pm.sample(njobs=4)
pm.energyplot(trace);
Auto-assigning NUTS sampler...
Initializing NUTS using ADVI...
Average Loss = 0.056672: 100%|██████████| 200000/200000 [00:14<00:00, 13997.00it/s]
Finished [100%]: Average Loss = 0.054276
100%|██████████| 1000/1000 [00:06<00:00, 163.63it/s]
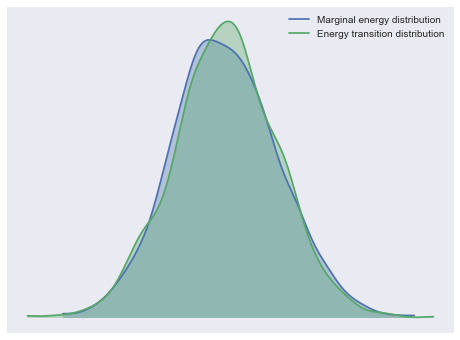
For more information on sampler stats and the energy plot, see here. For more information on identifying sampling problems and what to do about them, see here.
3.3 Variational inference¶
PyMC3 supports various Variational Inference techniques. While these
methods are much faster, they are often also less accurate and can lead
to biased inference. The main entry point is pymc3.fit().
In [38]:
with pm.Model() as model:
mu = pm.Normal('mu', mu=0, sd=1)
sd = pm.HalfNormal('sd', sd=1)
obs = pm.Normal('obs', mu=mu, sd=sd, observed=np.random.randn(100))
approx = pm.fit()
Average Loss = 146.58: 100%|██████████| 10000/10000 [00:00<00:00, 15134.18it/s]
Finished [100%]: Average Loss = 146.57
The returned Approximation object has various capabilities, like
drawing samples from the approximated posterior, which we can analyse
like a regular sampling run:
In [39]:
approx.sample(500)
Out[39]:
<MultiTrace: 1 chains, 500 iterations, 2 variables>
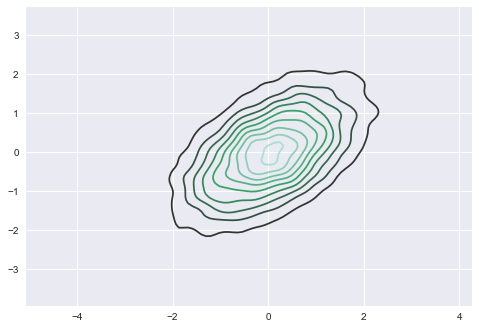
The variational submodule offers a lot of flexibility in which VI to
use and follows an object oriented design. For example, full-rank ADVI
estimates a full covariance matrix:
In [40]:
mu = pm.floatX([0., 0.])
cov = pm.floatX([[1, .5], [.5, 1.]])
with pm.Model() as model:
pm.MvNormal('x', mu=mu, cov=cov, shape=2)
approx = pm.fit(method='fullrank_advi')
Average Loss = 0.00061705: 100%|██████████| 10000/10000 [00:02<00:00, 3763.84it/s]
Finished [100%]: Average Loss = 0.00090201
An equivalent expression using the object-oriented interface is:
In [41]:
with pm.Model() as model:
pm.MvNormal('x', mu=mu, cov=cov, shape=2)
approx = pm.FullRankADVI().fit()
Average Loss = 0.0016698: 100%|██████████| 10000/10000 [00:02<00:00, 3345.98it/s]
Finished [100%]: Average Loss = 0.001701
In [42]:
plt.figure()
trace = approx.sample(10000)
sns.kdeplot(trace['x'])
Out[42]:
<matplotlib.axes._subplots.AxesSubplot at 0x11f4f2eb8>
Stein Variational Gradient Descent (SVGD) uses particles to estimate the posterior:
In [43]:
w = pm.floatX([.2, .8])
mu = pm.floatX([-.3, .5])
sd = pm.floatX([.1, .1])
with pm.Model() as model:
pm.NormalMixture('x', w=w, mu=mu, sd=sd)
approx = pm.fit(method=pm.SVGD(n_particles=200, jitter=1.))
100%|██████████| 10000/10000 [00:53<00:00, 188.00it/s]
In [44]:
plt.figure()
trace = approx.sample(10000)
sns.distplot(trace['x']);
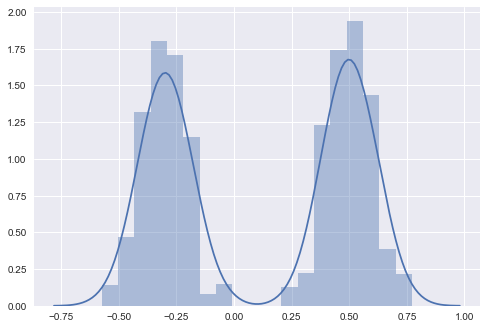
For more information on variational inference, see these examples.
4. Posterior Predictive Sampling¶
The sample_ppc() function performs prediction on hold-out data and
posterior predictive checks.
In [45]:
data = np.random.randn(100)
with pm.Model() as model:
mu = pm.Normal('mu', mu=0, sd=1)
sd = pm.HalfNormal('sd', sd=1)
obs = pm.Normal('obs', mu=mu, sd=sd, observed=data)
trace = pm.sample()
Auto-assigning NUTS sampler...
Initializing NUTS using ADVI...
Average Loss = 141.37: 100%|██████████| 200000/200000 [00:15<00:00, 12799.60it/s]
Finished [100%]: Average Loss = 141.37
100%|██████████| 1000/1000 [00:00<00:00, 1963.58it/s]
In [46]:
with model:
post_pred = pm.sample_ppc(trace, samples=500, size=len(data))
100%|██████████| 500/500 [00:06<00:00, 73.82it/s]
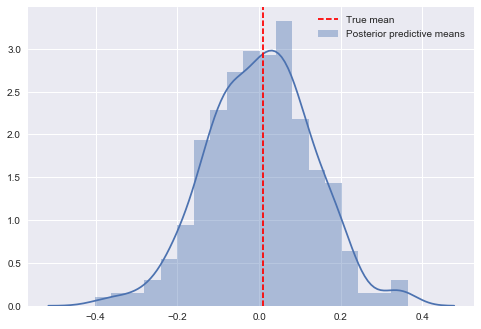
sample_ppc() returns a dict with a key for every observed node:
In [47]:
post_pred['obs'].shape
Out[47]:
(500, 100)
In [48]:
plt.figure()
ax = sns.distplot(post_pred['obs'].mean(axis=1), label='Posterior predictive means')
ax.axvline(data.mean(), color='r', ls='--', label='True mean')
ax.legend()
Out[48]:
<matplotlib.legend.Legend at 0x125eac748>
4.1 Predicting on hold-out data¶
In many cases you want to predict on unseen / hold-out data. This is
especially relevant in Probabilistic Machine Learning and Bayesian Deep
Learning. While we plan to improve the API in this regard, this can
currently be achieved with a theano.shared variable. These are
theano tensors whose values can be changed later. Otherwise they can be
passed into PyMC3 just like any other numpy array or tensor.
In [49]:
import theano
x = np.random.randn(100)
y = x > 0
x_shared = theano.shared(x)
y_shared = theano.shared(y)
with pm.Model() as model:
coeff = pm.Normal('x', mu=0, sd=1)
logistic = pm.math.sigmoid(coeff * x_shared)
pm.Bernoulli('obs', p=logistic, observed=y_shared)
trace = pm.sample()
Auto-assigning NUTS sampler...
Initializing NUTS using ADVI...
Average Loss = 21.931: 7%|▋ | 14453/200000 [00:01<00:12, 15315.19it/s]
Convergence archived at 15000
Interrupted at 15,000 [7%]: Average Loss = 26.836
100%|██████████| 1000/1000 [00:00<00:00, 2842.64it/s]
Now assume we want to predict on unseen data. For this we have to change
the values of x_shared and y_shared. Theoretically we don’t need
to set y_shared as we want to predict it but it has to match the
shape of x_shared.
In [50]:
x_shared.set_value([-1, 0, 1.])
y_shared.set_value([0, 0, 0]) # dummy values
with model:
post_pred = pm.sample_ppc(trace, samples=500)
100%|██████████| 500/500 [00:02<00:00, 178.87it/s]
In [51]:
post_pred['obs'].mean(axis=0)
Out[51]:
array([ 0.016, 0.474, 0.972])