Sampler statistics¶
When checking for convergence or when debugging a badly behaving sampler, it is often helpful to take a closer look at what the sampler is doing. For this purpose some samplers export statistics for each generated sample.
In [1]:
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sb
import pandas as pd
import pymc3 as pm
%matplotlib inline
As a minimal example we sample from a standard normal distribution:
In [2]:
model = pm.Model()
with model:
mu1 = pm.Normal("mu1", mu=0, sd=1, shape=10)
In [3]:
with model:
step = pm.NUTS()
trace = pm.sample(2000, tune=1000, init=None, step=step, njobs=2)
100%|██████████| 2000/2000 [00:01<00:00, 1361.25it/s]
NUTS provides the following statistics:
In [4]:
trace.stat_names
Out[4]:
{'depth',
'diverging',
'energy',
'energy_error',
'max_energy_error',
'mean_tree_accept',
'step_size',
'step_size_bar',
'tree_size',
'tune'}
mean_tree_accept: The mean acceptance probability for the tree that generated this sample. The mean of these values across all samples but the burn-in should be approximatelytarget_accept(the default for this is 0.8).diverging: Whether the trajectory for this sample diverged. If there are many diverging samples, this usually indicates that a region of the posterior has high curvature. Reparametrization can often help, but you can also try to increasetarget_acceptto something like 0.9 or 0.95.energy: The energy at the point in phase-space where the sample was accepted. This can be used to identify posteriors with problematically long tails. See below for an example.energy_error: The difference in energy between the start and the end of the trajectory. For a perfect integrator this would always be zero.max_energy_error: The maximum difference in energy along the whole trajectory.depth: The depth of the tree that was used to generate this sampletree_size: The number of leafs of the sampling tree, when the sample was accepted. This is usually a bit less than \(2 ^ \text{depth}\). If the tree size is large, the sampler is using a lot of leapfrog steps to find the next sample. This can for example happen if there are strong correlations in the posterior, if the posterior has long tails, if there are regions of high curvature (“funnels”), or if the variance estimates in the mass matrix are inaccurate. Reparametrisation of the model or estimating the posterior variances from past samples might help.tune: This isTrue, if step size adaptation was turned on when this sample was generated.step_size: The step size used for this sample.step_size_bar: The current best known step-size. After the tuning samples, the step size is set to this value. This should converge during tuning.
If the name of the statistic does not clash with the name of one of the variables, we can use indexing to get the values. The values for the chains will be concatenated.
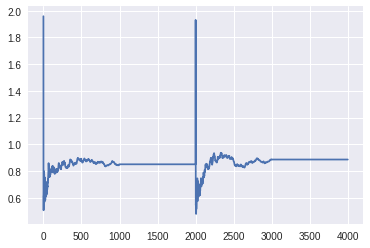
We can see that the step sizes converged after the 1000 tuning samples for both chains to about the same value. The first 2000 values are from chain 1, the second 2000 from chain 2.
In [5]:
plt.plot(trace['step_size_bar'])
Out[5]:
[<matplotlib.lines.Line2D at 0x7f234bfd5588>]
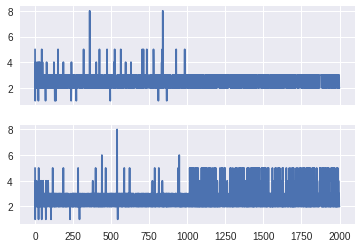
The get_sampler_stats method provides more control over which values
should be returned, and it also works if the name of the statistic is
the same as the name of one of the variables. We can use the chains
option, to control values from which chain should be returned, or we can
set combine=False to get the values for the individual chains:
In [6]:
sizes1, sizes2 = trace.get_sampler_stats('depth', combine=False)
fig, (ax1, ax2) = plt.subplots(2, 1, sharex=True, sharey=True)
ax1.plot(sizes1)
ax2.plot(sizes2)
Out[6]:
[<matplotlib.lines.Line2D at 0x7f23417d0dd8>]
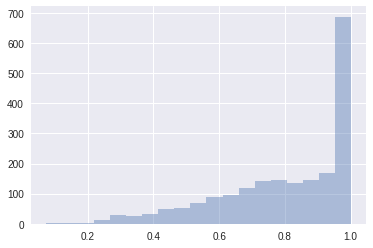
In [7]:
accept = trace.get_sampler_stats('mean_tree_accept', burn=1000)
sb.distplot(accept, kde=False)
Out[7]:
<matplotlib.axes._subplots.AxesSubplot at 0x7f23480810f0>
In [8]:
accept.mean()
Out[8]:
0.80329863296935067
Find the index of all diverging transitions:
In [9]:
trace['diverging'].nonzero()
Out[9]:
(array([], dtype=int64),)
It is often useful to compare the overall distribution of the energy levels with the change of energy between successive samples. Ideally, they should be very similar:
In [10]:
energy = trace['energy']
energy_diff = np.diff(energy)
sb.distplot(energy - energy.mean(), label='energy')
sb.distplot(energy_diff, label='energy diff')
plt.legend()
Out[10]:
<matplotlib.legend.Legend at 0x7f234168ada0>
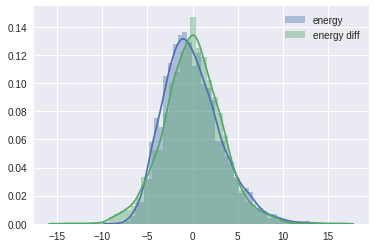
If the overall distribution of energy levels has longer tails, the efficiency of the sampler will deteriorate quickly.
Multiple samplers¶
If multiple samplers are used for the same model (e.g. for continuous and discrete variables), the exported values are merged or stacked along a new axis.
In [11]:
model = pm.Model()
with model:
mu1 = pm.Bernoulli("mu1", p=0.8)
mu2 = pm.Normal("mu2", mu=0, sd=1, shape=10)
In [12]:
with model:
step1 = pm.BinaryMetropolis([mu1])
step2 = pm.Metropolis([mu2])
trace = pm.sample(10000, init=None, step=[step1, step2], njobs=2, tune=1000)
100%|██████████| 10000/10000 [00:02<00:00, 3695.88it/s]
In [13]:
trace.stat_names
Out[13]:
{'accept', 'p_jump', 'tune'}
Both samplers export accept, so we get one acceptance probability
for each sampler:
In [14]:
trace.get_sampler_stats('accept')
Out[14]:
array([[ 1.00000000e+00, 2.99250475e-05],
[ 2.50000000e-01, 2.58944314e-04],
[ 1.00000000e+00, 5.89596665e-03],
...,
[ 2.50000000e-01, 7.71917301e-02],
[ 1.00000000e+00, 2.43450517e-01],
[ 1.00000000e+00, 2.40661294e-02]])